Sometimes we use transform: translateZ(0); or backface-visibility: hidden; to fix webkit-based browsers flicker caused by transition/animation, and it also fixes the image blur when using filters.
Tips for the devs ... directly from the Faria cave
18 June 2014
SVG in Compass
experimental support
With $experimental-support-for-svg, Compass brings a way to make websites compatible with modern browser.
Some function syntaxes like linear-gradient don’t have a clear syntax spec, different browsers have different implementations.
https://developer.mozilla.org/en-US/docs/Web/CSS/linear-gradient
For example IE won’t support linear-gradient(left, #ffffff, #dddddd), it has to be linear-gradient(to right, #ffffff, #dddddd).
So if you write left, Compass will write browser-specific prefixes -webkit and -moz but it won’t change the left for IE (which needs to right), so when you write the following code in sass, IE(10/11) will not display the linear-gradient background.
+background-image(linear-gradient(left, #ffffff, #dddddd))
So you can set the $experimental-support-for-svg to true to solve this problem with a svg-image
$experimental-support-for-svg: true
+background-image(linear-gradient(left, #ffffff, #dddddd))
That will generate a data URI based svg image like
background-image:url("data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlb..")
With $experimental-support-for-svg, Compass brings a way to make websites compatible with modern browser.
Some function syntaxes like linear-gradient don’t have a clear syntax spec, different browsers have different implementations.
https://developer.mozilla.org/en-US/docs/Web/CSS/linear-gradient
For example IE won’t support linear-gradient(left, #ffffff, #dddddd), it has to be linear-gradient(to right, #ffffff, #dddddd).
So if you write left, Compass will write browser-specific prefixes -webkit and -moz but it won’t change the left for IE (which needs to right), so when you write the following code in sass, IE(10/11) will not display the linear-gradient background.
+background-image(linear-gradient(left, #ffffff, #dddddd))So you can set the $experimental-support-for-svg to true to solve this problem with a svg-image
$experimental-support-for-svg: true
+background-image(linear-gradient(left, #ffffff, #dddddd))That will generate a data URI based svg image like
background-image:url("data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlb..")
18 June 2014
BigText
a js lib for justifying big text
Got some fun with this simple js plugin:
https://github.com/zachleat/BigText
Text size justification is based on font-size not its parent width or height. because it’s difficult to fill the parent element fully just by kerning text. This can help us to do this dynamically.
Check the demo wizard at http://www.zachleat.com/bigtext/demo/
Got some fun with this simple js plugin:
https://github.com/zachleat/BigText
Text size justification is based on font-size not its parent width or height. because it’s difficult to fill the parent element fully just by kerning text. This can help us to do this dynamically.
Check the demo wizard at http://www.zachleat.com/bigtext/demo/
18 June 2014
Merging arrays
and remove duplicates
Here is a small tip for ruby array operation
We have
a1 = ["a","b"]
a2 = ["b","c"]
Say we want to merge this two array to get a new array and it’s element must unique, you can
a3 = a1 + a2
a3.uniq!
# ["a","b","c"]
You can also do it like this
a1 | a2
# ["a","b","c"]
This is much quicker for our lazy fingers.
Here is a small tip for ruby array operation
We have
a1 = ["a","b"]
a2 = ["b","c"]
Say we want to merge this two array to get a new array and it’s element must unique, you can
a3 = a1 + a2
a3.uniq!
# ["a","b","c"]
You can also do it like this
a1 | a2
# ["a","b","c"]
This is much quicker for our lazy fingers.
18 June 2014
Git bisect
to track where it broke
Sometimes when the codebase is broken and you are sure it is working perfectly fine on a certain commit, then it’s time git bisect comes into place.
You start the bisect by:
git bisect start
git bisect good <COMMIT-SHA>
git bisect bad <COMMIT-SHA>
Once you specify GOOD and BAD commit for git bisect, it will checkout the central commit for you.
You then test the code and input the result for your testing:
git bisect bad # (or good)
Keep doing this and you will finally get the corrupted commit! That’s it.
Last thing, remember to exit the bisect mode after you finish by:
git bisect reset
Sometimes when the codebase is broken and you are sure it is working perfectly fine on a certain commit, then it’s time git bisect comes into place.
You start the bisect by:
git bisect start
git bisect good <COMMIT-SHA>
git bisect bad <COMMIT-SHA>
Once you specify GOOD and BAD commit for git bisect, it will checkout the central commit for you.
You then test the code and input the result for your testing:
git bisect bad # (or good)
Keep doing this and you will finally get the corrupted commit! That’s it.
Last thing, remember to exit the bisect mode after you finish by:
git bisect reset
18 June 2014
Avoid fork in threads
at least not with multi threads
A thread calling a fork is the only thread in the created child process. Fork doesn’t copy other threads.
What it mean the thread in your current process would not available in your child process.
Let’s see
thread = Thread.new { }
thread2 = Thread.new { }
fork {
puts "in child process #{Thread.list.count}"
}
puts "in main process #{Thread.list.count}"
# The output will be
#
# in main process 3
# in child process 1
So what is the problem? That mean when you use fork in a multithread program, the child process could not access the thread resource.
For example: Bunny is a multithread program client for Rabbitmq, we try to publish a message in main process and subscribe it in the child process through fork, then something bad happen, we still have the same queue instance, but the connection fails. Because the network I/O thread is not inherited, the connection could not be used in child process cause this fail.
require "bunny"
conn = Bunny.new
conn.start
ch = conn.create_channel
q = ch.queue("test1")
# publish a message to the default exchange which then gets routed to this queue
q.publish("Hello, everybody!")
puts "Main process queue object_id #{q.object_id}"
# fetch a message from the queue
# It would fail because bunny is multithread, and fork would not copy the thread.
# The output is
# ...continuation_queue.rb:25:in `pop': execution expired (Timeout::Error)
fork {
puts "Child process queue object_id #{q.object_id}"
delivery_info, metadata, payload = q.pop
puts "This is the message: #{payload}"
sleep (2)
}
conn.stop
So. Don’t fork in threads when you rely on a threadpool.
references:
A thread calling a fork is the only thread in the created child process. Fork doesn’t copy other threads. What it mean the thread in your current process would not available in your child process.
Let’s see
thread = Thread.new { }
thread2 = Thread.new { }
fork {
puts "in child process #{Thread.list.count}"
}
puts "in main process #{Thread.list.count}"
# The output will be
#
# in main process 3
# in child process 1So what is the problem? That mean when you use fork in a multithread program, the child process could not access the thread resource.
For example: Bunny is a multithread program client for Rabbitmq, we try to publish a message in main process and subscribe it in the child process through fork, then something bad happen, we still have the same queue instance, but the connection fails. Because the network I/O thread is not inherited, the connection could not be used in child process cause this fail.
require "bunny"
conn = Bunny.new
conn.start
ch = conn.create_channel
q = ch.queue("test1")
# publish a message to the default exchange which then gets routed to this queue
q.publish("Hello, everybody!")
puts "Main process queue object_id #{q.object_id}"
# fetch a message from the queue
# It would fail because bunny is multithread, and fork would not copy the thread.
# The output is
# ...continuation_queue.rb:25:in `pop': execution expired (Timeout::Error)
fork {
puts "Child process queue object_id #{q.object_id}"
delivery_info, metadata, payload = q.pop
puts "This is the message: #{payload}"
sleep (2)
}
conn.stopSo. Don’t fork in threads when you rely on a threadpool.
references:
12 June 2014
S3 backups
when you have massive amount of files
We use S3 to backup various kind of files on MB. We use the very convenient backup gem for that (we still use 3.9.0).
But at some point it appeared that backing up our audio recording was hammering disk IO on our server, because the syncer is calculating md5 footprint for each file each time a backup happens. When you get thousands of big files that is pretty expensive process (in our case 20k files and 50G total).
So I added a small trick there:
in Backup/models/backup_audio.rb
module Backup::Syncer::Cloud
class Base < Syncer::Base
def process_orphans
if @orphans.is_a?(Queue)
@orphans = @orphans.size.times.map { @orphans.shift }
end
"Older Files: #{ @orphans.count }"
end
end
end
Backup::Model.new(:backup_audio, 'Audio files Backup to S3') do
before do
system("/Backup/latest_audio.sh")
end
after do
FileUtils.rm_rf("/tmp/streams")
end
##
# Amazon Simple Storage Service [Syncer]
#
sync_with Cloud::S3 do |s3|
s3.access_key_id = "xxx"
s3.secret_access_key = "xxx"
s3.bucket = "bucket_backup"
s3.region = "us-east-1"
s3.path = "/mb_audio_backup"
s3.mirror = false
s3.thread_count = 50
s3.directories do |directory|
directory.add "/tmp/streams"
end
end
end
and in Backup/latest_audio.sh
#!/bin/sh
# isolate files changed in the last 3 days
TMPDIR=/tmp/streams
mkdir $TMPDIR
for i in `find /storage/audio/ -type f -cmin -4320`; do
ln -s $i $TMPDIR
done
It creates a fake backup dir with links to the files that actually changed in the last 3 days and patches the syncer to avoid flooding the logs with orphan files. When sometimes S3 upload fails on one file (and it happens from time to time for ‘amazonian’ reason) it will be caught on the next daily backup.
The result was pretty obvious on our disk usage with our daily backups:
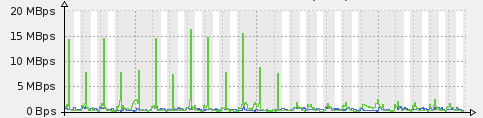
in the logs:
[2014/06/10 07:00:25][info] Summary:
[2014/06/10 07:00:25][info] Transferred Files: 5
[2014/06/10 07:00:25][info] Older Files: 22371
[2014/06/10 07:00:25][info] Unchanged Files: 16
[2014/06/10 07:00:25][info] Syncer::Cloud::S3 Finished!
[2014/06/10 07:00:25][info] Backup for 'Audio files Backup to S3 (backup_audio)' Completed Successfully in 00:00:22
[2014/06/10 07:00:25][info] After Hook Starting...
[2014/06/10 07:00:25][info] After Hook Finished.
We use S3 to backup various kind of files on MB. We use the very convenient backup gem for that (we still use 3.9.0).
But at some point it appeared that backing up our audio recording was hammering disk IO on our server, because the syncer is calculating md5 footprint for each file each time a backup happens. When you get thousands of big files that is pretty expensive process (in our case 20k files and 50G total).
So I added a small trick there:
in Backup/models/backup_audio.rb
module Backup::Syncer::Cloud
class Base < Syncer::Base
def process_orphans
if @orphans.is_a?(Queue)
@orphans = @orphans.size.times.map { @orphans.shift }
end
"Older Files: #{ @orphans.count }"
end
end
end
Backup::Model.new(:backup_audio, 'Audio files Backup to S3') do
before do
system("/Backup/latest_audio.sh")
end
after do
FileUtils.rm_rf("/tmp/streams")
end
##
# Amazon Simple Storage Service [Syncer]
#
sync_with Cloud::S3 do |s3|
s3.access_key_id = "xxx"
s3.secret_access_key = "xxx"
s3.bucket = "bucket_backup"
s3.region = "us-east-1"
s3.path = "/mb_audio_backup"
s3.mirror = false
s3.thread_count = 50
s3.directories do |directory|
directory.add "/tmp/streams"
end
end
endand in Backup/latest_audio.sh
#!/bin/sh
# isolate files changed in the last 3 days
TMPDIR=/tmp/streams
mkdir $TMPDIR
for i in `find /storage/audio/ -type f -cmin -4320`; do
ln -s $i $TMPDIR
doneIt creates a fake backup dir with links to the files that actually changed in the last 3 days and patches the syncer to avoid flooding the logs with orphan files. When sometimes S3 upload fails on one file (and it happens from time to time for ‘amazonian’ reason) it will be caught on the next daily backup.
The result was pretty obvious on our disk usage with our daily backups:
in the logs:
[2014/06/10 07:00:25][info] Summary:
[2014/06/10 07:00:25][info] Transferred Files: 5
[2014/06/10 07:00:25][info] Older Files: 22371
[2014/06/10 07:00:25][info] Unchanged Files: 16
[2014/06/10 07:00:25][info] Syncer::Cloud::S3 Finished!
[2014/06/10 07:00:25][info] Backup for 'Audio files Backup to S3 (backup_audio)' Completed Successfully in 00:00:22
[2014/06/10 07:00:25][info] After Hook Starting...
[2014/06/10 07:00:25][info] After Hook Finished.
12 June 2014
Capybara target window
to test links with target
In Capybara when you need to test a page that was opened by clicking a link with target="_blank", all you need to do is to write:
within_window(page.driver.browser.get_window_handles.last) do
...
some_code_here
...
end
Note! Beyond that code you’ll be at the page where you clicked that link.
update
The test will pass, but you will receive this message:
DEPRECATION WARNING: Passing string argument to #within_window is deprecated. Pass window object or lambda.
So now we should transform that code into:
within_window(windows.last) do
...
some_code_here
...
end
and everything should be fine :)
In Capybara when you need to test a page that was opened by clicking a link with target="_blank", all you need to do is to write:
within_window(page.driver.browser.get_window_handles.last) do
...
some_code_here
...
endNote! Beyond that code you’ll be at the page where you clicked that link.
update
The test will pass, but you will receive this message:
DEPRECATION WARNING: Passing string argument to #within_window is deprecated. Pass window object or lambda.
So now we should transform that code into:
within_window(windows.last) do
...
some_code_here
...
endand everything should be fine :)
12 June 2014
Sidekiq dynamic priority
by chosing your queue at runtime
Dynamic Sidekiq priority job
By default sidekiq uses “Queue” to prioritize jobs:
https://github.com/mperham/sidekiq/wiki/Advanced-Options
Then you can configure workers to use “high priority” queue.
But can we dynamically decide which queue at runtime?
Instead of YourWorker.perform_async(arg1, arg2),
there’s a low-level API that you can use:
Sidekiq::Client.push( {
'class' => YourWorker,
'queue' => your_queue,
'args' => [arg1, arg2]
})
That way you can decide which queue to use, at runtime.
Dynamic Sidekiq priority job
By default sidekiq uses “Queue” to prioritize jobs: https://github.com/mperham/sidekiq/wiki/Advanced-Options Then you can configure workers to use “high priority” queue.
But can we dynamically decide which queue at runtime?
Instead of YourWorker.perform_async(arg1, arg2),
there’s a low-level API that you can use:
Sidekiq::Client.push( {
'class' => YourWorker,
'queue' => your_queue,
'args' => [arg1, arg2]
})That way you can decide which queue to use, at runtime.
12 June 2014
Tagbar with Coffeetags
for coffeescript in vim
Tagbar provide a sidebar in vim to show the tags from ctags of current file. But ctags doesn’t support coffeescript, so we have to add tag rules manually in ~/.ctags or just add a config for tagbar, to make tagbar use CoffeeTags when we are editing file in coffeescript.
and add the following to .vimrc:
if executable('coffeetags')
let g:tagbar_type_coffee = {
\ 'ctagsbin' : 'coffeetags',
\ 'ctagsargs' : '',
\ 'kinds' : [
\ 'f:functions',
\ 'o:object',
\ ],
\ 'sro' : ".",
\ 'kind2scope' : {
\ 'f' : 'object',
\ 'o' : 'object',
\ }
\ }
endif
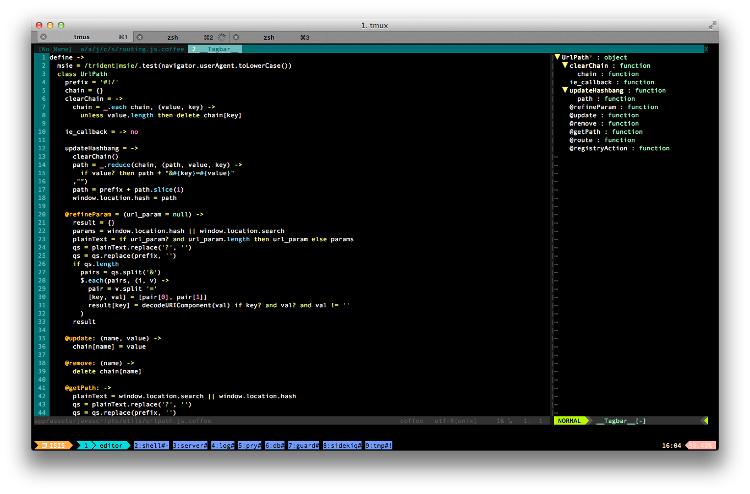
Tagbar provide a sidebar in vim to show the tags from ctags of current file. But ctags doesn’t support coffeescript, so we have to add tag rules manually in ~/.ctags or just add a config for tagbar, to make tagbar use CoffeeTags when we are editing file in coffeescript.
and add the following to .vimrc:
if executable('coffeetags')
let g:tagbar_type_coffee = {
\ 'ctagsbin' : 'coffeetags',
\ 'ctagsargs' : '',
\ 'kinds' : [
\ 'f:functions',
\ 'o:object',
\ ],
\ 'sro' : ".",
\ 'kind2scope' : {
\ 'f' : 'object',
\ 'o' : 'object',
\ }
\ }
endif